How language models are developed and adapted is covered, among other things, in the report "Large Language Models in Health and Care Services." [113]
Methods for adapting language models are not mutually exclusive. Pre-training involves training a model from scratch so that it can be adapted to Norwegian conditions from the very beginning. Post-training involves building on a pre-trained general model with data sources relevant to the health sector. An AI system that uses language models can also be improved and adapted to concrete use, for example through knowledge anchoring or through agentic AI. This chapter describes various ways to pre-train, post-train, knowledge-anchor, evaluate, and test large language models.
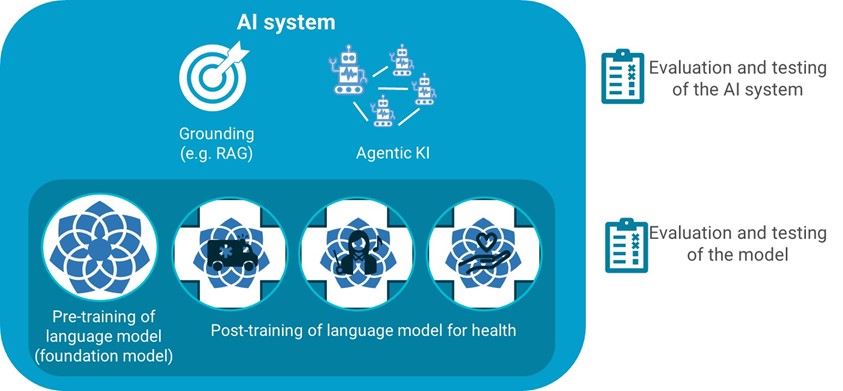
Pre-training of language models
Pre-training of large language models gives full control over the model and insight into the model's learning process. However, the approach is very costly, as it will require extensive amounts of relevant data and significant computational resources. GPT and Gemini are examples of large, market-leading pre-trained language models that have been developed from scratch. These are also called foundation models and are often delivered by large American technology companies. However, challenges are pointed out related to, among other things, explainability, accountability, sovereignty, and linguistic quality in these models [114]. As a response, several European countries have initiated developing their own pre-trained language models.
The large international foundation models have proven to be powerful and applicable in many areas and already contain some Norwegian language and are used in Norway. In Norway, there are several initiatives to develop Norwegian foundation models, both through BERT-based models like NorBERT and larger models like NorGPT from NorwAI and NORA.LLM models from the NORA consortium, for example NorMistral.
Many large international foundation models are pre-trained on significant amounts of general health professional knowledge. There are also international language models that are pre-trained from scratch specifically for health. An example is MedFound, which is trained on patient records and medical texts [115]. This model is much smaller than the larger international foundation models mentioned above. Such smaller models can be more energy efficient, but the areas of use is more limited since they are trained on less data.
The technology is rapidly evolving, and new models such as DeepSeek's language models R1 and Open R1 represent a new and more energy-efficient direction for how information can be retrieved and processed. This makes previous approaches, particularly BERT-based models, largely outdated for generative tasks, although they may still be useful for specific applications.
When choosing which pre-trained model to build on, it is important to consider whether it is open or closed. For open models, either the source code can be available and/or the training data can be known and documented. Conversely, access to source code and/or training foundation will be limited or not available for closed models. This makes it difficult, if not impossible, to explain and quality assure models derived from them.
Post-training of pre-trained language models (foundation models)
Although many foundation models already master some Norwegian language and are trained on some international health professional knowledge, they should be post-trained if they are to become better adapted to Norwegian conditions. Post-training involves building on a pre-trained general model with relevant data and can be based on one or more foundation models.
The National Library's NB-Whisper and Bineric's NorskGPT are examples of Norwegian, general (non-health professional) post-training.
Fine-tuning with Norwegian health professional language resources
Foundation models can be fine-tuned using domain-specific health professional resources as training data. A fine-tuned language model will then be much better at handling Norwegian professional language and terminology as well as health professional and health administrative knowledge and practice.
A foundation model can be fine-tuned to:
- a relatively large and general health professional language model. This will facilitate a common health professional language model for Norwegian health and care services that can be used and further developed by the entire sector, including public and private actors.
- several smaller and specialized language models, oriented toward different purposes (subject, specialty, or task). These are trained on texts belonging to a given task or specialty.
Such fine-tuning can be achieved in several ways. One possible approach is to train the foundation model further on Norwegian language, health professional texts so that the algorithms in the model are changed. This requires that the foundation model is open (see above). This form of fine-tuning requires significant computing power [116]. Another approach involves fine-tuning by adding layers outside the pre-trained model, which preserves the original model weights and therefore requires less computing power [117].
Regardless of approach, it is important to be aware that a language model will never be fully learned. Professional language, knowledge, and practice in health and care services are not constant but are updated in line with professional development in the field. It is therefore important to account for continuous learning when fine-tuning a language model. Methods for fine-tuning are an active area of research and can be facilitated by federated learning [118]. Another approach is to version and periodically release models with updated knowledge. This will require active management.
Continuous updating of language models
Large language models can be updated continuously by establishing a systematic follow-up and update mechanism so that, for example, new clinical guidelines, updated data, and changes in professional terminology can be quickly incorporated into the model. This can, for example, involve regular updates through continuous learning or periodic fine-tuning.
A feedback loop with clinical expertise can also be established, for example by including a mechanism for continuous feedback from health personnel using the model. The feedback is used to identify any errors or outdated recommendations so that the model can be revised and improved in line with current professional knowledge and practice.
Instruction tuning in line with health professional and administrative tasks
To handle health professional tasks, a language model must be specifically trained for them. Such tasks can be translations, interpretation, conveying information to patients, or creating drafts for patient records. This can be done by fine-tuning the language model using datasets containing examples of the tasks to be solved. The process can be iterative and involve humans providing feedback along the way.
The need for instruction tuning applies to both foundation models and fine-tuned models. Even if models are instruction-tuned in English beforehand, there may still be a need for specific Norwegian instruction tuning. This is particularly relevant for domains where precise understanding of Norwegian instructions is critical, or where cultural and subject-specific aspects are important.
Fine-tuning in line with Norwegian legislation, values, and ethics
A language model can be fine-tuned to function in line with Norwegian legislation, values, and ethical principles. Such adaptation can be done in several ways:
- through systematic training on examples that demonstrate desired ethical behavior
- using reinforcement learning with human feedback (RLHF) where humans evaluate the model's responses against defined ethical guidelines
- by building ethical principles into training data and evaluation criteria
The purpose is that the model's behavior and generated text should reflect and be consistent with defined ethical principles. This should be seen in connection with a national approach to common values and ethics. For health and care services, values such as confidentiality, self-determination, and non-harm are central. At the same time, one must account for the fact that values and ethical principles are not constant but evolve over time.
When using foreign models, it is important to investigate what values and principles are already built into the model and assess how these interact with or possibly deviate from Norwegian values and health service needs.
To comply with legislation, the adaptation process can include integrated security and privacy strategies that explicitly include measures to protect sensitive health data.
Knowledge grounding and agentic AI
Knowledge grounding is a technique for improving the quality and relevance of responses from a language model without changing the language model itself. Quality-assured and curated data sources such as internal or external knowledge bases can constitute a knowledge foundation.
RAG (Retrieval Augmented Generation) is one method for knowledge grounding that has proven promising as an effective alternative to health professional fine-tuning [119]. A prerequisite is that the knowledge base is relevant to Norwegian conditions. At the same time, the language model used must be able to handle languages in Norway.
It is still too early to determine whether the combination of RAG and large language models works sufficiently well for the relevant areas of use in the Norwegian health and care sector. There is a need for more experience and knowledge in the field for RAG to be recommended for large-scale use in health and care services.
When a RAG solution is used, knowledge is retrieved from predefined knowledge bases. The language model's function is primarily to interpret and phrase the question/instruction to find correct information in the knowledge base and then generate the response after information has been retrieved. The approach makes direct adaptation to the purpose of use possible, requires little computational and data resources, and can reduce errors and fabricated responses. The Norwegian Directorate of Health is testing RAG for the information service HelseSvar.
Example: HelseSvar
The Norwegian Directorate of Health has tested RAG technology to generate suggestions for answers to health questions from young people related to various areas, such as contraception, tobacco, and mental health. The goal is to make the work of healthcare personnel more efficient when they respond to young people who make contact through ung.no.
Several different language models have been tested, together with a RAG solution that uses a knowledge bank with previous questions and answers, or articles published online.
In the final report, it was concluded that "RAG and enterprise data provide professionally strong results. But it is necessary to improve the linguistic adaptation, especially for Nynorsk and simpler linguistic expressions, to make the AI assistants more accessible and user-friendly for young people." This requires processing texts and formulations adapted to the target group in the enterprise data that forms the basis for the RAG solution.
Furthermore, it concludes: "In the short term, we recommend that the AI solution HelseSvar (which uses RAG) is primarily used as a support tool for health responders, rather than as a self-help tool for citizens. The RAG solution delivers correct answers in 80–90% of cases, which illustrates a high degree of precision and reliability. Although the solution responds very well to health-related questions, it happens that it answers incorrectly due to misunderstandings of the context of the question, or unclear enterprise data. Human quality assurance is therefore necessary for health related questions."
After the report was published, the project continues to work with methods that improve response quality. This includes, for example, techniques for how responses are built up, especially through the use of agents that interpret the question, develop a plan for obtaining relevant information, and compose the response in a structured and controlled manner.
Source: "Report – HelseSvar. Concept study for an AI assistant for citizen-directed information." Internal report in the Norwegian Directorate of Health.
Agentic AI involves breaking down complex questions into smaller tasks and combining multiple tools that can answer tasks. The agent interprets the user's question and develops a structured workflow with specific steps to answer the question (see AI fact sheet Intelligence enhancement and control) [120].
Evaluation and testing of language models for Norwegian conditions
We lack national principles for testing, evaluation, and quality assurance of language models for Norwegian conditions, which is a challenge that applies to the entire public administration and not just the health and care sector.
Evaluation and testing can be done of both foundation models and fine-tuned models, among other things, to be able to compare and possibly choose the language model that is best suited for further training and adapted to the purpose of use. Evaluation and testing of an AI system is conducted to assess how well it performs in relation to the intended use.
To be able to assess a language model's performance requires a structured approach to evaluation of the various aspects described in section 4.1. A central aspect is language, where the model can be tested in how it masters Norwegian medical professional terminology, or how it masters Bokmål, Nynorsk, and in some contexts also Sami in health professional context. The precision level in health professional communication can also be assessed.
Contextual understanding is equally important, where tests can show how the model performs in accordance with Norwegian health service organization and structure. This can apply to Norwegian treatment guidelines and procedures, as well as local administrative routines and documentation requirements.
To ensure thorough evaluation, a stepwise approach to testing is possible. This can start with basic evaluation of language and security, proceed to domain-specific testing for the health sector, continue with use-area-specific testing, and context-specific testing in the implementation environment, then preferably as part of an AI system. If the language model is part of an AI system that falls under the Medical Device Regulation, specific requirements for testing and validation will be imposed according to this law [121].
[114] https://www.nora.ai/news/2024/we-need-open-norwegian-language-models.html and https://teknologiradet.no/en/publication/generative-artificial-intelligence-in-norway/
[116] Full parameter fine-tuning https://arxiv.org/abs/2306.09782
[117] Parameter efficient fine tune-tuning (PEFT) https://arxiv.org/abs/2410.21228
[118] https://medium.com/@bhat_aparna1/federated-learning-with-large-language-models-balancing-ai-innovation-and-data-privacy-2425b3e0044e
[119] RAG (Retrieval-Augmented Generation) is an AI method that combines information retrieval with text generation to improve the quality and relevance of responses.
[120] AI fact sheets will be published here https://www.helsedirektoratet.no/digitalisering-og-e-helse/kunstig-intelligens/ki-faktaark
[121] https://lovdata.no/dokument/NL/lov/1995-01-12-6 and https://eur-lex.europa.eu/eli/reg/2017/745/oj/eng