Power BI er et rapporterings- og analyseverktøy som gjør det mulig å samle data fra mange forskjellige kilder, både gjennom skytjenester og statiske filer, for så å presentere data i samlende rapporter og visualiseringer. Den største forskjellen fra andre verktøy, som for eksempel Excel, er den dynamiske tilnærmingen til visualisering, hvor brukergrensesnittet er optimalisert for å kunne fremstille data i ulike hierarkier og med forskjellig vinkling i en og samme rapport. En Power BI rapport vil for mange skape muligheter for en datadrevet styringstilnærming, uten at det krever omfattende opplæring og store utviklerressurser. For å visualisere og analysere klimagassutslippene i spesialisthelsetjenesten har Power BI blitt benyttet for å fremstille store mengder data. Gjennom det dynamiske og interaktive verktøyet kan innrapportert utslippsdata fremstilles på en brukervennlig måte, og dermed støtte prosesser for styring av klimagassutslipp.
Power BI rapport
Power BI som verktøy
Det er ofte slik at programvare er optimalisert og best egnet til noen få spesifikke oppgaver. For Power BI gjelder dette rapportering av historisk data. Sanntidsrapportering har også blitt bedre den siste tiden, men dette er fortsatt et bruksområde under utvikling. Prognoser eller andre måter å forsøke å tallfeste fremtiden på er enda ikke noe programvaren egner seg til, og den type oppgaver kan best løses med alternative verktøy.
Datavask for fremstillingene av klimagassutslipp i Power BI
Data benyttet i Power BI ble anskaffet fra Sykehusbygg HF og omfatter klimaregnskapet til helseforetakene gitt i Tabell 6. Fremgangsmåten for uthenting av data er illustrert i Figur 3. Denne dataen ble manuelt hentet ut fra Sykehusbygg HF sin portal for føring av klimaregnskap, for så å bli datavasket i Power Query i Excel hvor programmeringsspråket M ble benyttet. Datavask innebærer å strukturere og kvalitetssjekke dataen hentet ut fra systemet. Selve datavaskingen ble gjennomført med M-koden vist i Figur 4, med respektive navn på foretak og år for hvert dokument. Felter som ble endret er i koden merket med ##. I datavasken ble formatet endret fra wide- til long-format for å strukturere dataen vertikalt på observasjonsnivå. Long-format bidrar til at det er enklere å filtrere ut ønsket data i Power BI.
I denne prosessen ble det valgt å kun ta med helseforetak fra de fire regionale helseforetakene Helse Midt, Helse Sør-Øst, Helse Vest, Helse Nord samt de nasjonale selskapene. Grunnlaget for denne beslutningen kom av at disse regionene med tilhørende foretak hadde gjennomført grundig rapportering av utslippene tilknyttet Scope 1 og 2 (samt på enkelte kategorier i Scope 3) over flere år.
| Helse Midt-Norge | |
| Helse Midt-Norge RHF | Hemit |
| Helse Sør-Øst | |
| Akershus universitetssykehus | Sykehuset Innlandet |
| Helse Nord | |
| Helgelandssykehuset | Helse Nord IKT |
| Helse Vest | |
| Helse Stavanger | Helse Vest IKT |
| Nasjonale Selskap | |
| HDO HF | Sykehusbygg HF |


Kvalitetssikring av data
Ved manuell datavasking er det risiko for menneskelige feil. For å minimere denne risikoen er det lagt stor vekt på kontinuerlig kvalitetssjekk. Tilretteleggelse for kontinuerlig kontroll ble gjort ved en nedenfra og opp tilnærming, hvor mindre datasett kombineres for å lage større datasett. Først ble data for hvert helseforetak, som er laveste nivå, datavasket og kontrollert. Deretter ble disse datasettene slått sammen for å utgjøre data til respektive regionale helseforetak. Samledokumentene for hver region ble slått sammen til et enkeltdokument som inneholder data for alle helseforetak. Etter hver sammenslåing ble det utført kontrollsjekker og beregninger for å sikre datakvaliteten. Summeringer gjort i Power BI ble eksempelvis sjekket opp mot manuell summering av data fra rapporteringssystemet. Det ble også gjennomført funksjonstesting av filtre for å kontrollere at de fungerer som tiltenkt og med korrekte tall.
Forutsetninger for bruk av Power BI
Bruk av Power BI til visualisering av klimagassutslipp i spesialisthelsetjenesten forutsetter et solid datagrunnlag med tilstrekkelig kvalitet. For at ulike funksjoner og filtreringer skal fungere trengs det data i mange dimensjoner, og på flere nivåer (RHF, HF osv.). Det er dessuten viktig at dataen er sammenlignbar. Dette har vært en utfordring da data fra flere kilder med ulikt format blir presentert samlet i Power BI rapporten om klimagassutslipp. Scope 3 tallene som årlig er rapportert inn til Sykehusbygg HF er kun tatt med for å se forskjeller mellom de oppskalerte tallene og faktisk innrapporterte tall. De er ikke tatt med som en del av beregnet totalutslipp. Estimerte tall for hele Scope 3 basert på oppskaleringen fra Helse Bergen (Referanse) erstatter disse. Dette er gjort for å ikke blande rapportert data med estimert data innenfor en Scope-kategori. Det har med andre ord vært essensielt å skille på faktisk rapportert data og estimert data for å ikke gi misvisende resultater i Power BI.
Figur 5 viser et skjermbilde av hvordan rapporten i Power BI ser ut og Tabell 7 er en forklaring til nøkkeltall som er tatt med i rapporten. Veiledning for bruk av rapporten finnes i en egen brukerrveileder.
| Nøkkeltall | Datagrunnlag |
|---|---|
| Utslipp / sysselsatt | Antall sysselsatte er hentet fra rapporteringssystemet. Det bemerkes at det er forskjeller mellom antall sysselsatte rapportert i SSB og rapporteringssystemet.
|
| Utslipp / driftskostnad (M) | Driftskostnader er hentet fra proff.no og SSB.
|
| Utslipp / kvadratmeter | Bygningsareal hentet fra rapporteringssystemet.
|
| Totalt utslipp | Totalt utslipp bestående av oppskalert data fra Scope 3 og innrapportert data for Scope 1 og 2 for de 4 helseregionene. |
Utklipp av rapport i Power BI
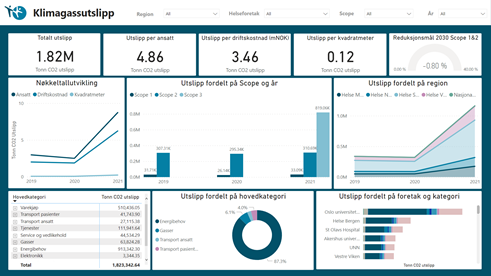
Hovedfunn fra fremstillingen i Power BI
Hovedfunnene konkluderer ikke med årsaker til funn, men trekker frem interessante observasjoner og tendenser observert fra fremstillingen i Power BI.
- Estimert Scope 3 utslipp for 2021 utgjør nesten like mye som energibehovet over tre år for hele spesialisthelsetjenesten.
- Generell trend er at 2020 var et år med mindre utslipp registrert enn i 2019 og 2021.
- Nøkkeltall for Scope 1 og Scope 2 har en synkende trend over tidsperioden 2019-2021.