Sjølv med betydelege framsteg i ytinga til store språkmodellar, kan dei ikkje brukast utan vidare i den norske helse- og omsorgstenesta. Problem som hallusinasjonar, innebygde fordommar og utfordringar med personvernproduksjon av tilsynelatande truverdig feilinformasjon, krev merksemd. Det blir spesielt viktig å forbetre og tilpasse KI-modeller til kulturen og språket som blir brukt i norsk helseteneste, å redusere skjeivheiter/bias i treningsdata og å utvikle robuste metodar for å validere innhald generert av KI, slik at språkmodellar kan brukast trygt og effektivt i helsesektoren.
Kjeldene peiker på fleire spørsmål, utfordringar og bekymringar knytt til språkmodellar, mellom anna:
- Utvikling og finjustering av språkmodeller
Utfordringar knyter seg til tilgang til og kvalitet på treningsdata, datakraft, miljøavtrykk, kostnad, nytte og risiko og validering. - Bruk av språkmodellar
Det er framleis risiko for at generative språkmodellar hallusinerer og skaper uriktig informasjon. Andre bekymringar knyter seg til kvalitet, skeivheiter (bias), etikk, gjennomsiktigheit, ansvar og kompetanse. - Forvaltning av språkmodellar
Det er opne spørsmål knytte til korleis språkmodellar forvaltast, om vi treng nasjonal forvaltning, og om det er risiko for maktkonsentrasjon.
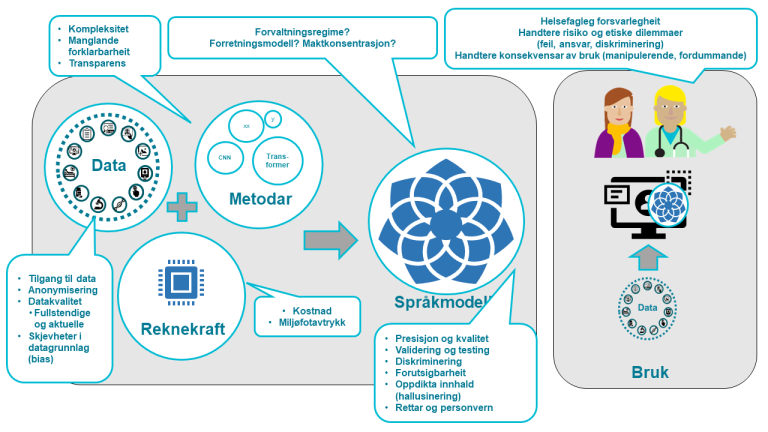
Desse problemstillingane er i større grad konkretiserte i vedlegg A.